Bridging Local Observation and Global Simulation in Closed-Loop Traffic Modeling
1The University of Hong Kong · 2Beihang University · *Equal contribution · †Corresponding author
CRAFT, a Contextual pReference Alignment Framework for Traffic Simulation, bridges this local-to-global mismatch via self-supervised failure discovery and preference-guided test-time alignment.
for CAT-K
for SMART
at least 1.0 s early
at the 9 s horizon
Overview
Can policies learned from locally observed driving logs remain behaviorally rational when executed in globally contextualized closed-loop simulation?
Autoregressive traffic simulators learn from ego-centric driving logs, where surrounding context can be incomplete due to perception limits and occlusions. When these models are rolled out in globally observable simulation, incomplete context-action associations can lead to abnormal stops, unsafe interactions, and rule violations.
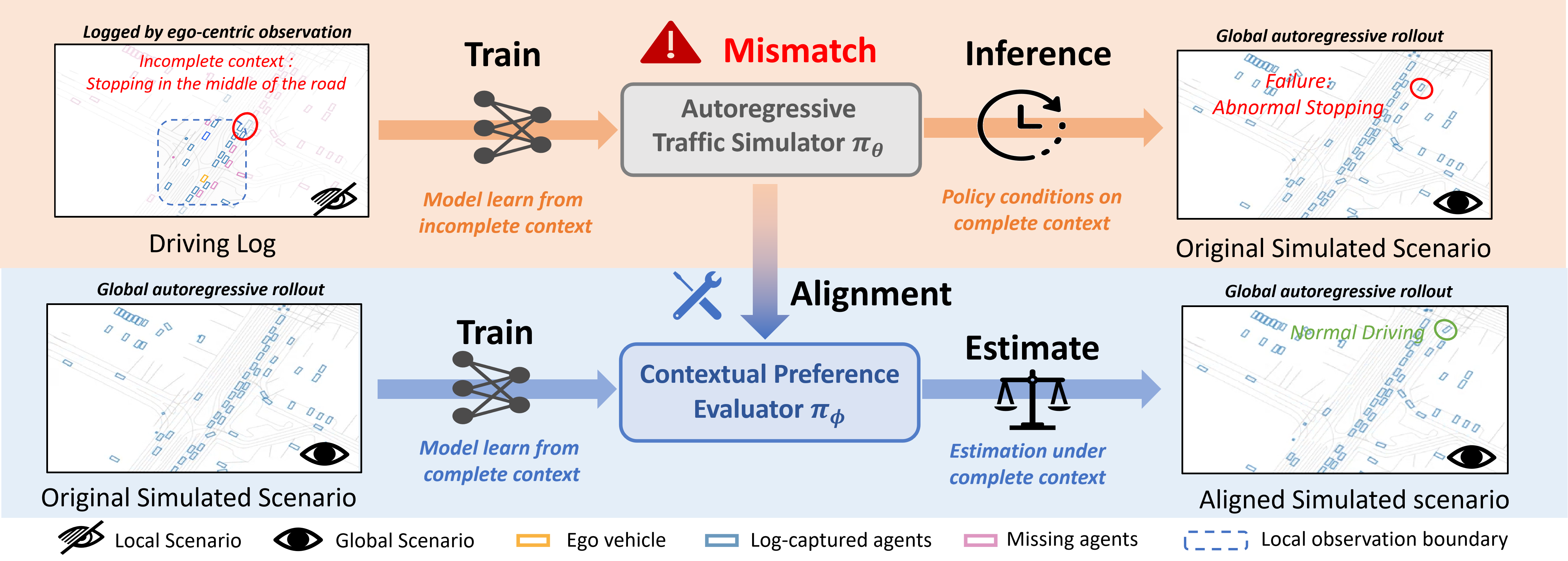
Method
CRAFT turns simulator-induced failures into preference guidance.
CRAFT treats the simulator itself as a globally observable sandbox. Starting from logged initial states, the base simulator generates diverse what-if rollouts that self-expose failure modes induced by incomplete observational context. These failures are grounded with human-aligned driving priors and converted into preference supervision for a Contextual Preference Evaluator (CPE), which assesses the rationality of generated behaviors under complete scene context.
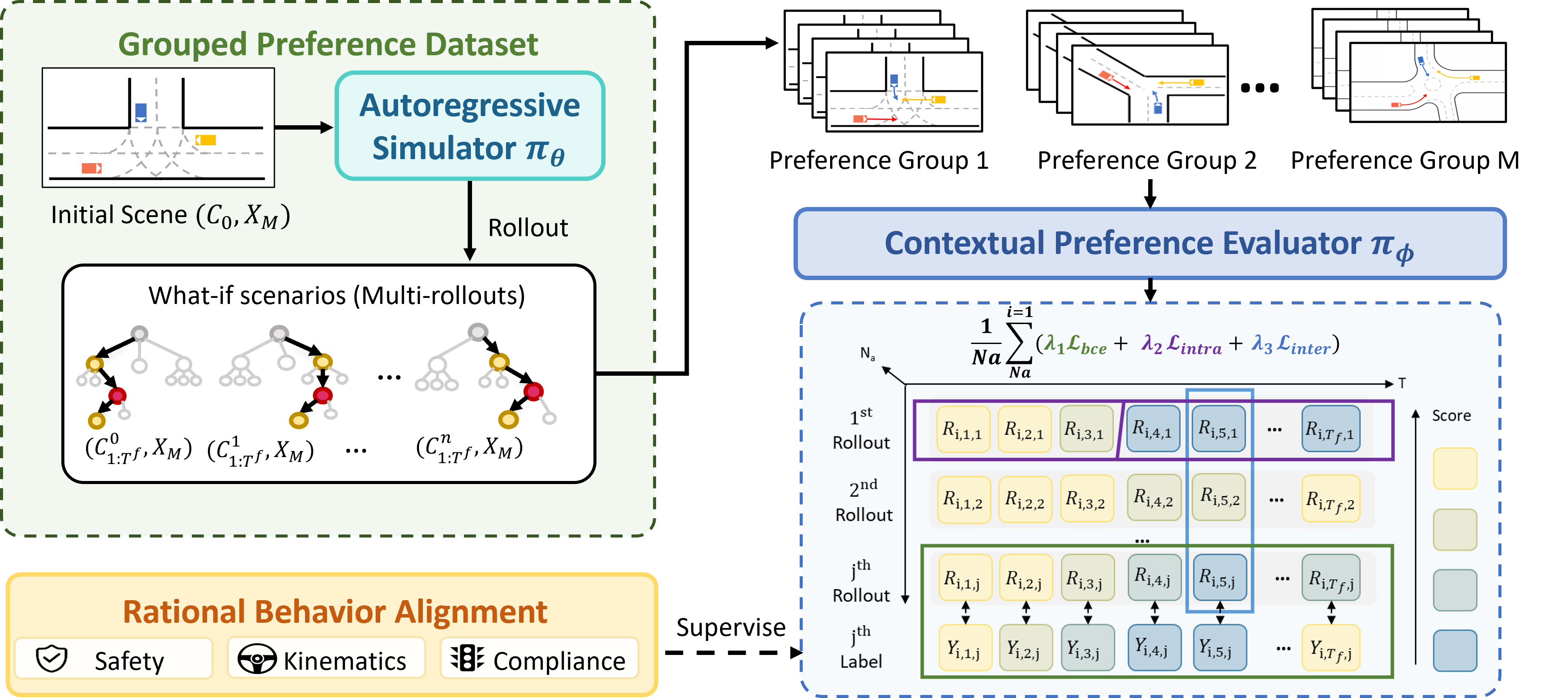
Training
Construct grouped complete-context what-if rollouts.
The base simulator performs stochastic rollouts with diverse random seeds from the same logged initial scene. The resulting preference dataset is organized as grouped alternative futures, supporting token-level supervision and inter-rollout preference learning.
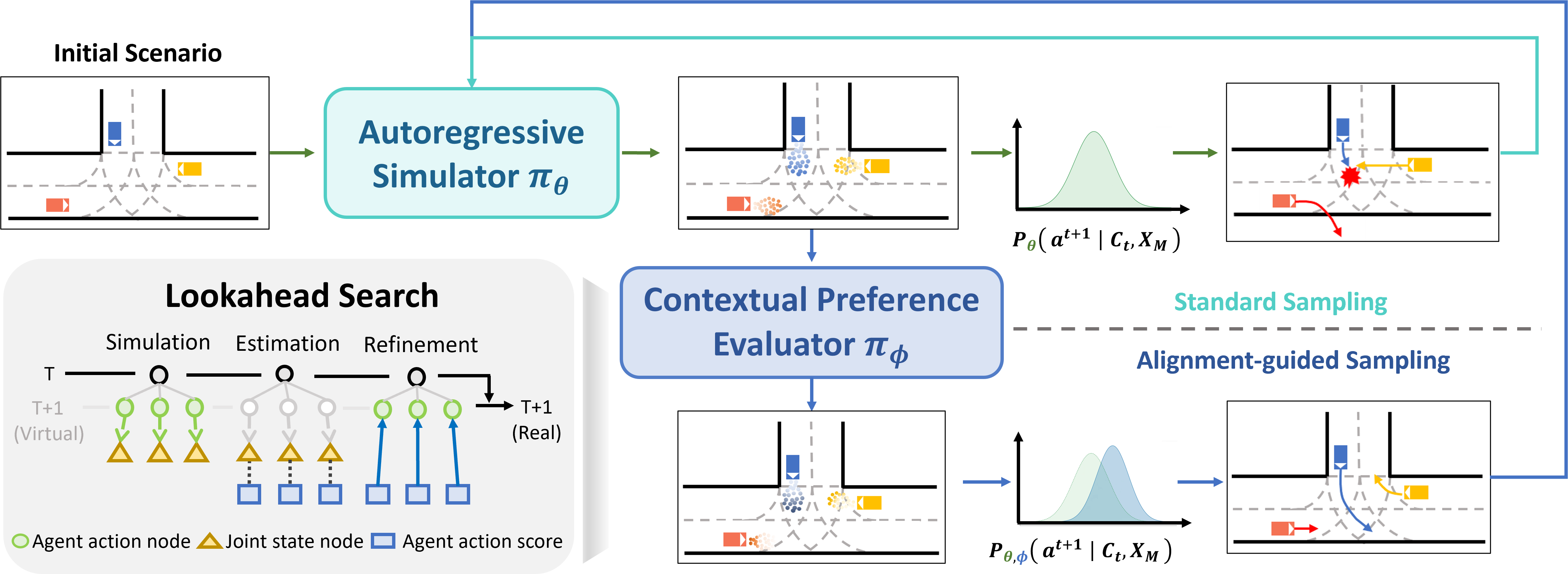
Inference
Reweight autoregressive decoding before action execution.
At each simulation step, CPE evaluates next-step candidates through one-step lookahead scenes and calibrates the simulator's next-token distribution before action execution.
Qualitative Rollouts
CRAFT guides closed-loop rollouts toward globally coherent traffic behavior.
Each scenario compares the baseline simulator with CRAFT under the same initial scene. CRAFT uses complete-context preference guidance to suppress locally plausible but globally inconsistent actions.
Baseline
CRAFT
Traffic-signal compliance
The baseline selects an action that violates the traffic signal, while CRAFT suppresses the violating candidate and maintains rule-compliant behavior.
Baseline
CRAFT
Abnormal-stop mitigation
The baseline produces an unexplained stop under the complete simulated context, whereas CRAFT guides the rollout toward smoother forward motion and preserves traffic flow.
Baseline
CRAFT
Safer multi-agent interaction
The baseline rollout leads to an unsafe interaction pattern, while CRAFT recalibrates candidate actions using contextual preference scores and produces a more coherent multi-agent behavior.
Baseline
CRAFT
Self-recovery under initial perturbations
The baseline struggles to recover from the initial perturbation, while CRAFT guides the vehicle back toward normal driving behavior under the complete simulated context.
Open-loop Eval.
Open-loop Eval.
Open-loop contextual preference evaluation
CPE estimates agent-time preference scores for generated behaviors under the complete simulated scene. In this visualization, green indicates a high preference score close to 1, red indicates a low preference score close to 0, and yellow indicates an intermediate score around 0.5, with colors gradually transitioning from green to red.
Main results
CRAFT improves closed-loop behavioral rationality.
CRAFT improves closed-loop behavioral rationality while maintaining competitive distributional realism. CPE functions as a plug-in alignment module for different simulators, amortizing human-aligned criteria into dense contextual preference scores and enabling more stable probability calibration during decoding.
| Base Model | Strategy | JSD (× 10−2) ↓ | Collision (%) ↓ | Offroad (%) ↓ | Traffic (%) ↓ P-Sc. | ||||
|---|---|---|---|---|---|---|---|---|---|
| Spd. | Ang. | Dist. | P-Ag. | P-Sc. | P-Ag. | P-Sc. | |||
| Log | Log replay | 0.00 | 0.00 | 0.00 | 0.56 | 5.20 | 1.59 | 14.40 | 20.70 |
| GUMP | Top-K | 4.78 | 5.41 | 11.36 | 4.06 | 36.30 | 3.80 | 26.90 | 32.70 |
| SMART | Top-K | 1.07 | 3.23 | 0.56 | 3.13 | 15.10 | 2.52 | 19.10 | 38.80 |
| CAT-K | Top-K | 1.02 | 2.96 | 0.53 | 3.41 | 15.70 | 2.54 | 19.50 | 36.50 |
| R1Sim | Top-K | 1.05 | 3.16 | 0.56 | 3.36 | 15.50 | 2.23 | 16.30 | 36.60 |
| CAT-K | Auto-labeler | 1.19 | 3.02 | 0.67 | 3.21 | 15.50 | 2.57 | 20.30 | 36.70 |
| CAT-K | CRAFT | 0.92 | 2.20 | 0.69 | 2.46 | 10.80 | 2.26 | 16.60 | 26.60 |
| SMART | CRAFT | 0.91 | 2.20 | 0.72 | 2.60 | 11.90 | 2.06 | 17.10 | 25.90 |
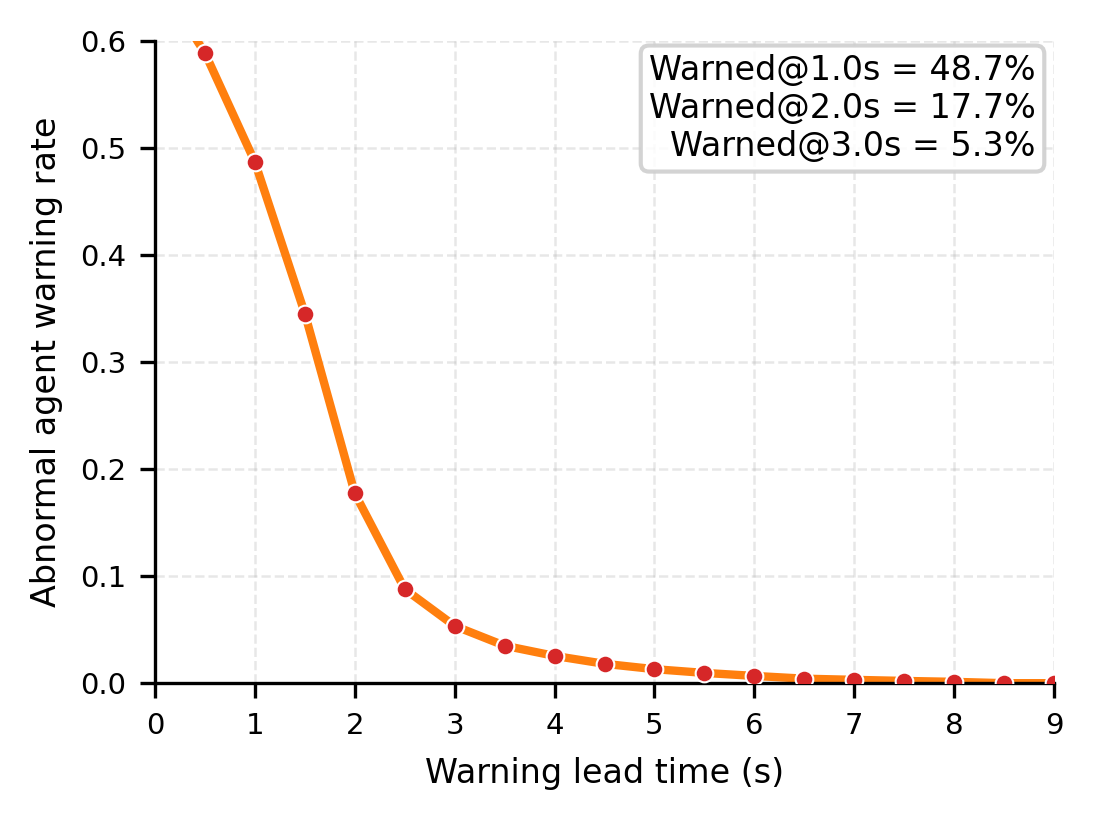
Test-time alignment analysis
CPE identifies risky action distributions before failures materialize and mitigates long-horizon error accumulation.
This proactive signal enables test-time correction before execution, whereas rule-based evaluators usually react only after explicit violations have occurred.

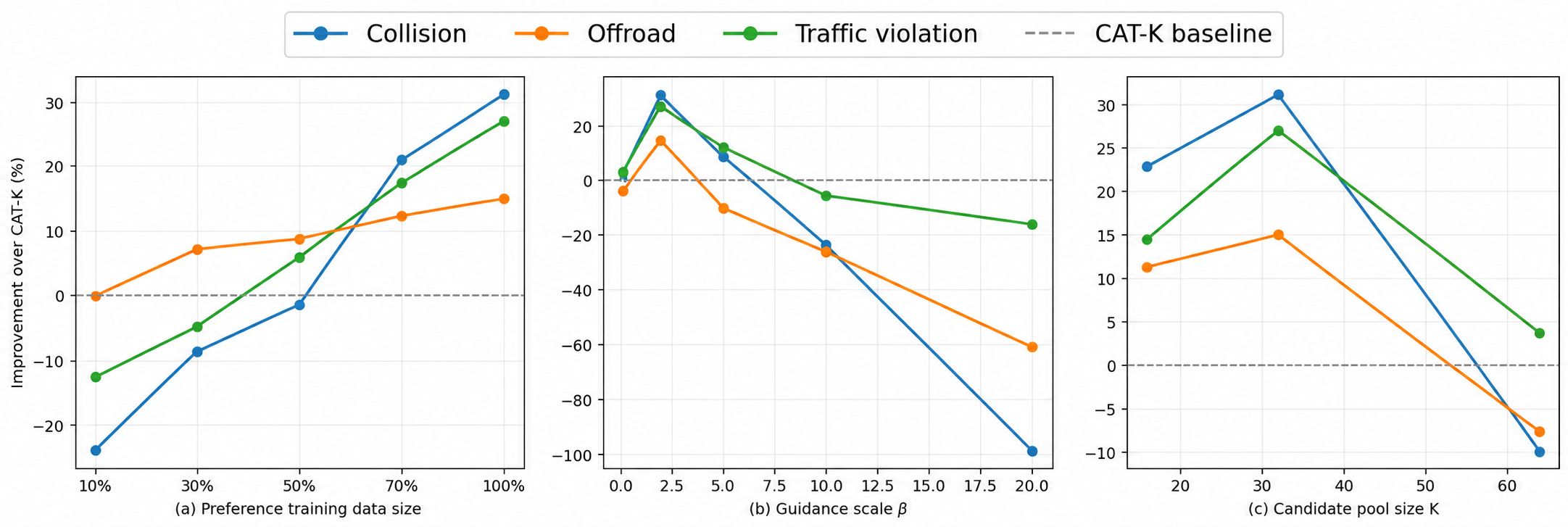
Robustness
Training scale, guidance strength, and candidate size jointly affect test-time alignment.
Increasing the preference-training data consistently improves behavioral metrics, indicating that CPE benefits from broader coverage of simulator-induced failure modes. At inference time, the guidance scale β controls the strength of calibration: a small β provides limited correction, while an overly large β over-calibrates the base distribution and degrades performance. Increasing the candidate pool from 16 to 32 improves guidance quality, but a larger pool introduces noisier candidates and reduces stability.
Contributions
From incomplete log imitation to complete-context preference alignment.
Local-to-global mismatch
Imitation learning on ego-centric logs leads to incomplete context-action associations that degrade closed-loop behavior.
Contextual Preference Evaluator
CPE learns complete-context behavioral preferences from simulator-induced failures grounded by human-aligned driving priors.
Plug-in test-time guidance
CPE is deployed as a plug-in test-time guidance module for autoregressive decoding, improving behavioral rationality while preserving competitive realism.
Citation
BibTeX
@inproceedings{anonymous2026craft,
title = {Bridging Local Observation and Global Simulation in Closed-Loop Traffic Modeling},
author = {Ziyan Wang and Tan Xiang and Peng Chen and Xintao Yan},
booktitle = {},
year = {2026}
}